Objective
The goal of this project is to implement Latent Dirichlet Allocation (LDA) for topic modeling to identify and analyze hidden thematic structures within a large collection of textual data. This project aims to provide insights into the main topics discussed in the dataset and to help categorize and summarize the content effectively.
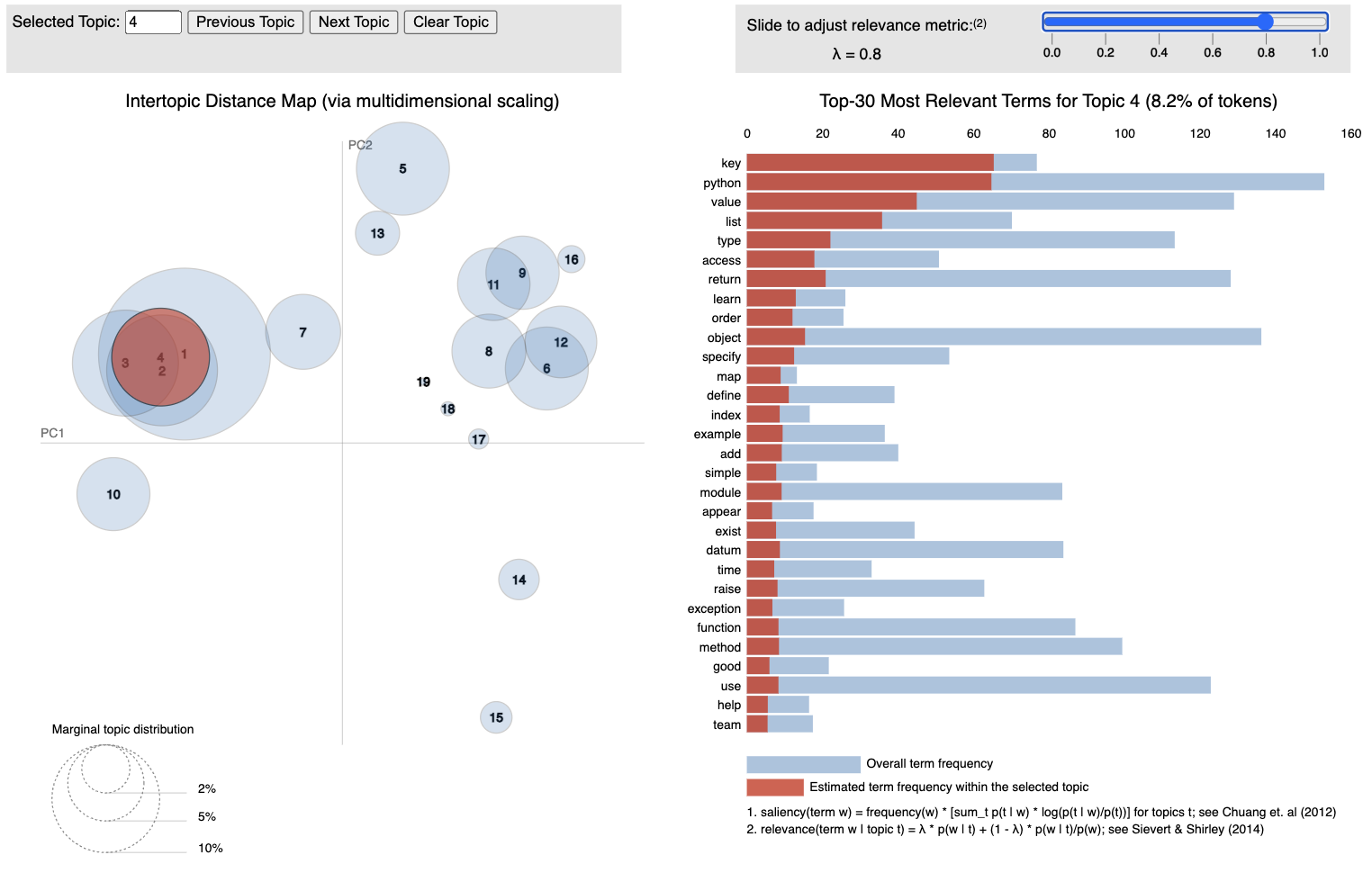
Project Description
Data Collection
Gather a substantial corpus of text data from various sources relevant to the study. This can include articles, blogs, reviews, research papers, or any textual content suitable for topic modeling.
Data Preprocessing
Clean and preprocess the text data by performing steps such as tokenization, removing stop words, stemming, and lemmatization. Ensure the data is in a format suitable for LDA input.
Exploratory Data Analysis (EDA)
Conduct an initial analysis of the data to understand its structure and key characteristics. Visualize the data distribution, word frequency, and other relevant metrics.
Model Implementation
Implement the LDA algorithm using a suitable library such as Gensim or Scikit-learn. Determine the optimal number of topics through methods like coherence scores or perplexity.
Model Training
Train the LDA model on the preprocessed dataset. Tune hyperparameters to achieve the best performance and ensure the model accurately captures the underlying topics.
Hyperparameter Tuning
- Optimize key hyperparameters such as the number of topics (num_topics), document-topic distribution prior (alpha), topic-word distribution prior (beta), and the number of iterations.
- Utilize methods such as grid search, random search, or Bayesian optimization to find the best parameter settings.
- Evaluate model performance using coherence scores and perplexity to ensure the topics are meaningful and interpretable.
Topic Extraction and Visualization
Extract the topics identified by the LDA model along with their associated keywords. Visualize the topics using techniques such as word clouds, topic distribution charts, and intertopic distance maps.
Topic Analysis and Interpretation
Analyze the extracted topics to interpret their meaning and relevance. Label the topics based on the keywords and context, and provide a comprehensive summary of each topic.
Application and Insights
Apply the model to new text data to demonstrate its effectiveness in identifying topics in unseen documents. Discuss the insights gained from the topic analysis and potential applications in areas such as content recommendation, document clustering, and trend analysis.
API Development
- Develop a RESTful API using Flask or FastAPI to serve the LDA model, allowing users to submit text data and receive topic modeling results.
- Implement endpoints for data preprocessing, model training, and topic extraction.
- Ensure the API is well-documented, secure, and scalable to handle multiple requests.
Reporting and Documentation
- Compile a detailed report documenting the methodology, implementation, results, and conclusions. Include visualizations, model performance metrics, and interpretations to support the findings.
- Provide API documentation detailing the usage, endpoints, and example requests/responses.
Tools and Technologies
- Programming Languages: Python
- Libraries: Gensim, Scikit-learn, NLTK, SpaCy, Matplotlib, Seaborn, Flask/FastAPI (for API development)
- Data Visualization Tools: Wordcloud, PyLDAvis
- Documentation: Jupyter Notebook, Markdown, Swagger/OpenAPI (for API documentation)
Expected Outcomes
- A trained LDA model capable of identifying and extracting meaningful topics from the text corpus.
- Visualizations and reports that effectively communicate the topics and insights derived from the analysis.
- A RESTful API that provides easy access to the LDA model for topic modeling on new text data.
- Practical applications of the model in real-world scenarios, demonstrating its value in text analysis and content categorization.